
Engenharia computacional para um mundo centrado em dados
O quarto paradigma da ciência
Durante uma palestra proferida na Califórnia em 2009 para o Computer Science and Telecommunications Board – National Research Council (NRC- CSTB), o renomado cientista da computação Jerry Nicholas “Jim” Gray (1944 – 2012), pontuou o surgimento do quarto paradigma da ciência. Ao utilizar o termo “eScience”, Gray queria dizer que a exploração científica seria grandemente influenciada pelo uso intensivo dos dados nos anos vindouros [1].
A evolução dos supercomputadores nesses últimos vinte anos elevou a capacidade de compreensão da natureza e permitiu que a ciência subisse mais um degrau na escada do conhecimento. A fim de entender o que é o quarto paradigma da ciência, vejamos quais são os três primeiros retrocedendo no tempo.
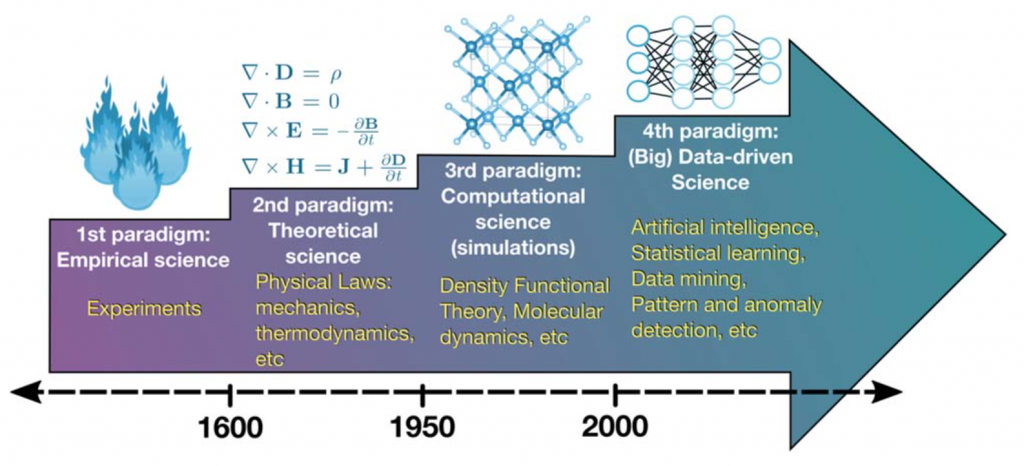
Há alguns milhares de anos, a ciência era essencialmente empírica. Tentava-se compreender os fenômenos naturais pela observação. Há algumas centenas de anos, equações, modelos e generalizações possibilitaram que a ciência se tornasse teórica, ou seja, passou-se a descrever com clareza e tecnicidade como um certo fenômeno funcionava. De algumas décadas para cá, as simulações de alta complexidade revelaram o terceiro pilar da ciência, tornando-a computacional. Atualmente, o amálgama entre teoria, experimentação e computação gerou uma vertente de exploração dos dados. Em outras palavras, poderíamos dizer que a ciência agora possui uma quarta faceta. Ela se tornou “datificada”.
Os dados são exploráveis porque um dia puderam ser capturados, mensurados, processados e simulados. Diante disso, a ciência atual é:
- Experimental;
- Teórica;
- Computacional e
- Datificada,
sendo o último paradigma a consumação dos três anteriores.
Ciência e Engenharia Computacional: o que é isso?
A Ciência e Engenharia Computacional, internacionalmente conhecida pelo acrônimo CSE (Computational Science and Engineering) é uma área interdisciplinar que compreende a ciência da computação, matemática aplicada, biologia e outras áreas do núcleo STEM (Science, Technology, Engineering, and Mathematics) voltada à resolução de problemas práticos das engenharias. A característica peculiar da CSE é o uso de métodos numéricos e sua integração com modelos matemáticos para subsidiar simulações computacionais e a resolução de equações diferenciais ordinárias ou parciais.
Equações diferenciais descrevem uma ampla variedade de fenômenos físicos, desde a absorção de um fármaco pelo organismo humano em escala nanométrica, até as ondas de choque macroscópicas causadas pela explosão de uma dinamite. Estes são apenas dois exemplos de situações que interessariam a indústria de biotecnologia e de construção ocorrendo em escalas extremamente distintas. Portanto, a CSE é afeita a problemas do mundo real caracterizados por multi-escalas pelos quais se compreende a dinâmica intrínseca de um fenômeno complexo modelável analiticamente.
Por que a CSE importa em um mundo de dados?
Embora em muitas áreas já se saiba com riqueza de detalhes como mecanismos intrínsecos de sistemas dinâmicos funcionam, em outras, este não é o caso. A indisponibilidade de dados em certos domínios do conhecimento decorre, principalmente, da dificuldade de capturá-los e coletá-los, seja pela inexistência de infraestrutura tecnológica, seja pelo alto investimento necessário para obtê-los. Um exemplo é a exploração da subsuperfície terreste. Dominar o conhecimento acerca da mecânica das rochas, a salinidade de aquíferos, o potencial geotérmico, ou a constituição química do gás natural nas partes mais baixas do planeta equivale a adentrar dezenas, centenas ou milhares de quilômetros na litosfera. Essa não é uma tarefa fácil. Pelo contrário, há tantas variáveis, riscos e custos envolvidos que sua execução pode ser inviabilizada.
A CSE entra em cena para preencher lacunas que os “dados”, por si só, não conseguem fechar. Uma vez que a exploração de dados só é exequível quando os próprios dados estão disponíveis, seria impossível explorar dados acerca de algo desconhecido. Claramente, seria paradoxal. Para dar outra ilustração, tomemos o exemplo das imagens digitais. A tecnologia atual provê condições suficientes para tirarmos fotos de milhares de objetos, seres e indivíduos (p.ex. uma formiga, um prédio, um planeta) sem qualquer dificuldade.
Processar imagens, hoje em dia, é um dos grandes carros-chefe para que modelos de inteligência artificial sejam implementados com precisão. Mas a manipulação de imagens só é possível por causa do progresso na física, óptica álgebra linear – afinal, imagens são matrizes – e ciência dos materiais – para construir carcaças de celulares, câmeras DSLR e satélites.
Aqui, cabe uma pergunta: será que no processos de fabricação desses componentes materiais, ninguém apelou para simulações computacionais? É bem improvável, porque nenhum gestor aprovaria o envio de um satélite responsável por fotografar o oceano Atlântico para o espaço sem ter uma margem aceitável de confiabilidade de que ele orbitaria corretamente e cumpriria seu propósito com segurança. E como se adquire essa confiabilidade? Vai-se para um laboratório, cria-se um protótipo e faz-se 1, 2, 10, 1.000, 100.000 simulações, até que se reduzam ao máximo as incertezas.
Estando em algum lugar entre o terceiro e o quarto paradigma, a CSE não apenas intermedia a análise de incertezas, como também simula processos, assim gerando economia de recursos. A CSE usa o primeiro, o segundo e o terceiro na transição para o quarto paradigma e, naturalmente, agrega valor a processos de um mundo que vive em transição tecnológica.
Ciência de Dados para criação de valor na Engenharia
A Ciência de Dados (data science) ganhou expressividade recentemente, embora seja um legado da Estatística tradicional. Como área independente, ainda busca seu espaço. Citando Cao [2],
“(…) uma compreensão abrangente e aprofundada do que é ciência de dados e o que pode ser alcançado com ciência de dados e pesquisa analítica, educação e economia ainda requer consenso.”
Gil Press, no artigo A Very Short History of Data Science, fez uma síntese histórica da ciência de dados com uma linguagem não acadêmica e de fácil compreensão. Ele assinalou que, desde 1962, quando o estatístico John Tukey (1915 – 2000) escreveu um artigo seminal sobre o futuro da análise de dados, a ciência de dados vem sendo gestada e preparada para assumir um papel transformador. Definições para a ciência de dados são encontradas na literatura sob variadas perspectivas. Na perspectiva de alto nível [2], de forma simplória,
“Ciência de Dados é a ciência dos dados ou o estudo dos dados”
e, na disciplinar, é
“um novo campo interdisciplinar que sintetiza e se constrói sobre a estatística, informática, computação, comunicação, gestão e sociologia para estudar dados e seus ambientes (incluindo domínios e outros aspectos contextuais, tais como sociais e organizacionais), a fim de transformar dados em insights e decisões seguindo um pensamento e uma metodologia dado > conhecimento > sabedoria“.
De acordo com o NIST (NIST 1500-1, 2015, EUA), órgão americano com funções similares às da ABNT,
“Ciência de Dados é a extração do conhecimento útil diretamente a partir de dados através de um processo de descoberta ou de formulação e teste de hipóteses.”
Valendo-se de um neologismo, Igual e Seguí [3] destacam que:
“a novidade da ciência de dados não está enraizada no conhecimento científico mais recente, mas em uma mudança disruptiva em nossa sociedade que foi causada pela evolução da tecnologia: a datificação. A datificação é o processo de renderização em aspectos de dados do mundo que nunca foram quantificados antes.”
De maneira mais detalhada, o International Journal of Data Science and Analytics, uma das revistas mais proeminentes em assuntos relacionados à ciência e análise de dados, assim descreve a área:
“a ciência de dados foi estabelecida como um importante campo científico emergente e um paradigma que impulsiona a evolução da pesquisa em disciplinas como estatística, ciência da computação e ciência da inteligência, e a transformação prática em domínios como ciência, engenharia, setor público, negócios, ciências sociais e estilo de vida. O campo abrange as áreas maiores da inteligência artificial, análise de dados, aprendizado de máquina, reconhecimento de padrões, compreensão de linguagem natural e manipulação de big data. Também aborda novos desafios científicos relacionados que vão desde a captura de dados, criação, armazenamento, recuperação e compartilhamento, análise, otimização e visualização, até análise integradora em recursos complexos heterogêneos e interdependentes para melhor tomada de decisão, colaboração e, em última análise, criação de valor.”
Do exposto, vemos que a ciência de dados é um processo evolutivo que excede as fronteiras das disciplinas tradicionais que a sustentam. Assim como os três outros paradigmas científicos conquistaram seu espaço com o passar do tempo, a ciência de dados é um composto autossuficiente de ferramentas com momentum próprio que não apenas estará no ápice científico, como também consolidará o quarto paradigma. Apesar disso, é importante compreender o ponto nevrálgico da ciência de dados: a criação de valor. Em particular, devemos entender como este valor se materializa na engenharia através do desenvolvimento de tecnologias e produtos inovadores.
Engenharia Computacional e Ciência de Dados são áreas interdisciplinares que resultam da interseção entre áreas terceiras. Comparando-as, percebemos que a característica mais distintiva entre ambas é a presença dos métodos numéricos e das simulações, que sobressai melhor na primeira área do que na segunda. A Figura abaixo propõe dois diagramas para destacar esta diferença, cujo autor assim resume: “Ciência de Dados é a arte de gerar percepções, conhecimentos e previsões através da aplicação de métodos em um conjunto de dados; a [CSE] é a arte de desenvolver modelos validados (simulação) para obter uma melhor compreensão do comportamento de um sistema”.
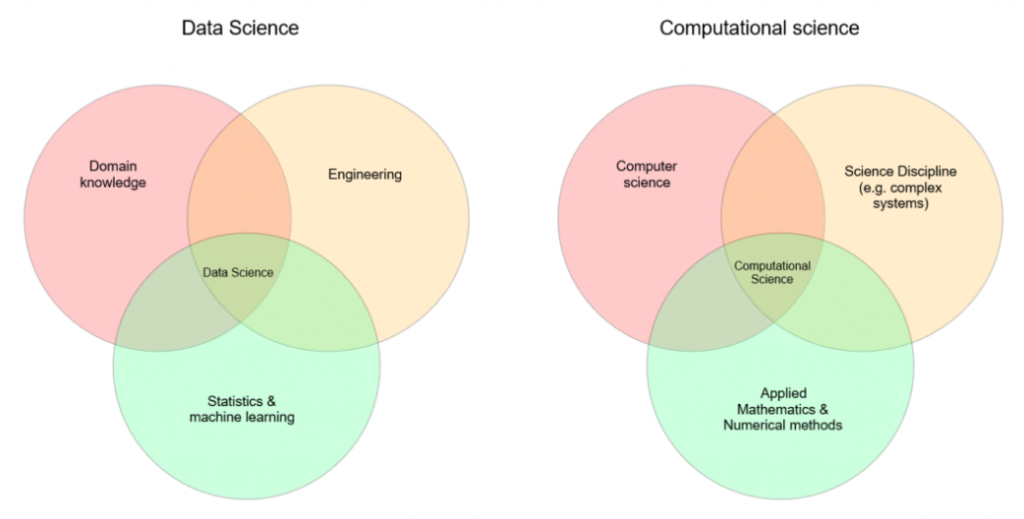
Neste texto, tratamos da ciência de dados como um termo amplo, mas vale frisar que diversos perfis derivados de “cientista de dados” são reconhecidos, tais como o de analista de dados e engenheiro(a) de dados. O documento oficial NIST 1500-1 é um bom ponto de referência para entender como esses perfis são caracterizados para o mercado de trabalho, assim como os artigos [4] e [5] o são, no aspecto acadêmico-educacional.
Engenharia centrada em dados: um novo ramo na árvore do futuro?
Mark Girolami, um professor de Engenharia Civil em Cambridge, liderou um grande programa de ciência de dados e inteligência artificial no Alan Turing Institute entre os anos de 2017 e 2020. Em sua percepção, a ciência de dados já havia se impregnado nas engenharias de tal forma que a inauguração de um novo termo para descrever essa interseção crescente seria justificável. Ele o chamou de engenharia centrada em dados (data-centric engineering, ou DCE).
Segundo Girolami [6], a DCE é explicada por um desenvolvimento substancial que impacta as engenharias, profissões associadas, suas práticas e também a política. Ao relembrar que a engenharia erigiu-se sobre dados desde seus primórdios, citou em seu artigo uma clássica fala de Lord Kelvin de 1889:
“Quando você pode medir o que está falando e expressar isso em números, você sabe alguma coisa sobre aquilo; quando não o pode expressar em números, seu conhecimento é escasso e insatisfatório; pode ser o princípio do conhecimento, mas você, em seus pensamentos, empurrou parcamente a fronteira da ciência.” [tradução livre]
Em suma, “medir é saber”. Girolami então pontuou que dados derivados da observação e medição experimentais foram os responsáveis por conduzir o desenvolvimento da filosofia natural e impulsionar o estado-da-técnica da engenharia por todo o século XIX. Em suas palavras,
“os dados sempre estiveram no coração da ciência e da prática na engenharia”.
Com a irrupção da DCE, uma pergunta que se faz é: seria a DCE um novo ramo na árvore do futuro da ciência de dados? Enquanto uma resposta objetiva é aguardada, poderíamos intuir, com base na opinião de vários experts que se reuniram no DCEng Summit, realizado no último setembro, em Londres, que as engenharias não serão mais as mesmas daqui para a frente. É consensual que o big data abriu enormes oportunidades para praticamente todas as áreas da engenharia – Aeronáutica, Civil, Mecânica, Offshore, entre outras – haja vista o nível de detalhamento provido por muitos bancos de dados quanto no que tange à compreensão de variados fenômenos que foram observados e medidos experimentalmente ao longo de décadas. Entretanto, uma gama de desafios acompanha essa evolução furtivamente. Ética e privacidade na gestão de dados, lentidão da difusão tecnológica em países de baixa renda e carência de profissionais qualificados e currículos contemporâneos são alguns deles.
Ley et al. [7], emitindo pontos de vista sobre como a DCE se projeta em suas áreas de atuação – estatística, engenharia e desenvolvimento de software –, concluíram que:
- o pensamento centrado em dados tornou-se necessário em vários domínios do conhecimento e a riqueza por eles disponibilizada acelerará a pesquisa no âmbito da engenharia de maneira imensurável;
- dados solitários não valem muita coisa e podem transmitir mensagens equivocadas se não forem analisados com cuidado e geridos de forma segura;
- pelo fato de a educação baseada em dados ser uma habilidade indispensável para a formação de futuros engenheiros, as universidades, empresas e gestores devem se mobilizar para assegurar um currículo interdisciplinar que forme profissionais com “mente aberta” e explore habilidades flexíveis capazes de lidar com dados.
Na Engenharia Mecânica, em particular, o conceito de ciência de dados mecanicista (mechanistic data science, MDS) e sua incorporação na educação de engenheiros, bem como de estudantes de nível médio nos Estados Unidos foi recentemente debatida no 16th USCCM e na conferência MMLDT-CSET 2021. A proposta da MDS é explanada, por exemplo, nesta apresentação do Prof. Wing Kam Liu da Northwestern University.
Regimes de dados: do small data para o big data
Cunhou-se recentemente o termo datasfera global (global datasphere) para aludir ao arcabouço de dados existente no mundo, sejam os armazenados, não circulantes, sejam os transmitidos, continuamente em fluxo. Em um relatório encomendado pela Seagate à empresa IDC [8], projetou-se que a datasfera romperá a estupenda marca de 175 zetabytes de dados em em 2025. Não apenas isso. As expectativas são de que a datasfera continuará em infindável expansão tal qual um hipotético disco rígido com capacidade de armazenamento ilimitada. A IDC estima que, em 2025, por exemplo, 49% dos dados armazenados no mundo residirão em ambientes públicos na nuvem.
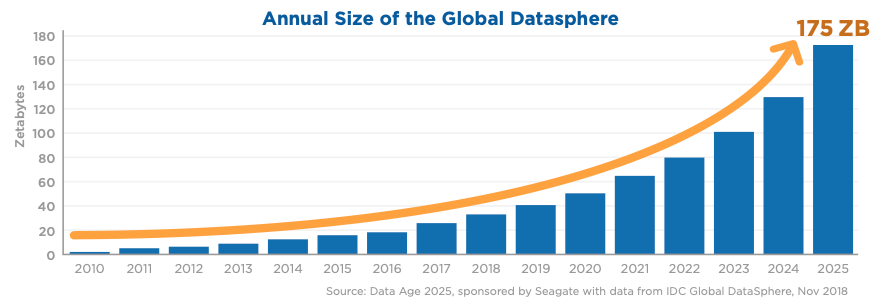
O ritmo voraz com que a datasfera tem se movido assemelha-se a um fluido escoante que transiciona de um regime laminar, estavél, não turbulento, em que tudo corre “suavemente”, para um regime turbulento, imprevisível, não controlável, no qual nada “para quieto”. Esta analogia reflete a transição progressiva e impetuosa da informação, a qual tem deixado o regime de pequenos dados (small data) rumo à dominância absoluta do regime de grandes dados (big data). Chiesa apud. Mayer-Schönberger e Cukier sublinha [9]:
“No mundo do big data, (…) não teremos mais que nos concentrar na aleatoriedade; em vez disso, os dados nos mostrarão tendências e correlações que nos oferecem indicações originais e preciosas. As correlações não nos dirão exatamente por que algo acontece, mas pelo menos nos alertarão que [de fato] as correlações são inúteis em um mundo dominado por pequenos dados, mas no contexto do big data, elas emergem em toda sua relevância. ” (CHIESA, p. 30)
O jargão de “pequenos” e “grandes” dados já era utilizado eventualmente na literatura técnica, mas nos últimos dois anos a frequência com que aparece aumentou. No âmbito da ciência da computação, o regime de pequenos dados é costumeiramente associado à escassez de um banco de dados. Esta condição é inerente a aplicações de inteligência artificial (IA) e aprendizado de máquina, quando a finalidade é realizar predições ou reconhecer padrões. No bojo da IA, é necessário dispor de fartos insumos legendados (labels) para treinamento, testagem e generalização, isto é, objetos que alimentarão um algoritmo que conduz a máquina a aprender por experiência. Algoritmos de aprendizagem profunda (deep learning) aplicados ao reconhecimento de expressões faciais, por exemplo, podem ter problemas de desempenho quando operam no regime de pequenos dados [10]. Em outras aplicações, como a interpretação de imagens sísmicas no setor de petróleo e gás, este desafio se apresenta em proporções similares.
Enquanto alguns setores econômicos já usufruem das benesses proporcionadas pelo big data, uma realidade que, gera competitividade entre players do mercado, outros ainda estão em transição. Para estes setores remanescentes, que ainda estão na esteira do big data, migrarem efetivamente do regime de pequenos dados para o reino incandescente do big data, a engenharia computacional apresenta-se como um de seus aliados potenciais.
Aprendizado de máquina informado por Física
O cenário transicional entre os regimes de pequenos dados e grandes dados é o que predomina na prática. Neste contexto, uma área emana do enlace entre aprendizado de máquina, matemática aplicada e computação científica é a que estuda o aprendizado de máquina informado por Física (physics-informed machine learning, ou PIML). Nas palavras de Karniadakis et al. [11], PIML é
“o processo pelo qual o conhecimento prévio extraído de nossa compreensão observacional, empírica, física ou matemática do mundo pode ser alavancado para melhorar o desempenho de um algoritmo de aprendizagem.”
Antes de penetrarmos no cerne do PIML, é preciso compreender esse interstício entre os regimes de dados.
No regime de pequenos dados, assume-se que a “Física” do fenômeno de interesse é satisfatoriamente conhecida, isto é, as leis, os princípios e as equações que o governam. Na teoria matemática, todas essas características unem-se em torno do que chamamos de problema de valor de contorno (PVC). Grosso modo, um PVC é formado por uma equação diferencial que descreve o funcionamento de um sistema e por condições impostas que determinam sua evolução. PVCs geram soluções matemáticas bem definidas quando são considerados bem postos.
No regime de grandes dados, sabe-se bem pouco ou quase nada acerca da Física do fenômeno, mas a quantidade de dados disponíveis sobre o fenômeno subjacente é expressiva. Nesta situação, bancos de dados são desenvolvidos por algum meio de coleta ou medição e os modelos baseados em dados dão a tônica na explicação do fenômeno.
Entretanto, existe um “meio-termo” entre essas duas instâncias em que tanto a Física quanto os dados sobre o fenômeno subjacente são conhecidos apenas parcialmente. Este interstício é o regime transicional dos dados, no qual é necessário integrar as leis físicas e o conhecimento prévio obtido a fim de tapar “buracos”. É aqui que o PIML entra.
A existência desses “buracos” decorre, por exemplo, do desconhecimento de como tal fenômeno se comporta em uma posição do espaço ou do tempo onde nenhuma informação é sabida a seu respeito, ou de conhecimento indistinto. Um exemplo disso é a determinação da origem ou da velocidade de propagação de manchas de óleo no oceano (relembre o caso de 2019, quando pesquisadores da COPPE/UFRJ inferiram a origem das manchas de óleo na costa do Nordeste brasileiro por meio de simulações computacionais de alto desempenho). No regime transicional, a física é usada para complementar modelos de aprendizado e preencher as lacunas existentes. Este é um cenário de dados ausentes, ou interrompidos (gappy data ou missing data), às vezes contaminado por ruídos (noisy data).
O PIML é a própria sinergia entre a aprendizagem de máquina e a modelagem multifísica/multiescala tradicionalmente empregada na engenharia. Sua proposta é a construção de algoritmos de aprendizagem de máquina que nos conduzam a respostas fisicamente consistentes. O PIML faz isso através do controle do viés, elemento constituinte de um sistema de aprendizado de máquina. Três abordagens são majoritárias:
- Viés observacional: o treinamento de um sistema de aprendizado é conduzido de forma que ele aprenda funções, campos vetoriais e operadores diferenciais que expressam a estrutura física dos dados.
- Viés indutivo: o sistema de aprendizado é induzido a aprender através da incorporação de leis e princípios físicos na forma de restrições matemáticas, isto é, intervenções customizadas realizadas na arquitetura do modelo que o informam acerca da “Física” de interesse.
- Viés de aprendizagem: neste caso, escolhas apropriadas para a função loss são realizadas através de ajustes finos, da introdução de restrições e da imposição de penalidades que favorecem a convergência do aprendizado, de forma que a solução se acomoda à Física fundamental em nível aproximado.
Cada abordagem tem vantagens e limitações. Elas não são mutuamente exclusivos. Pelo contrário, se aplicadas de forma híbrida, são capazes de produzir uma ampla classe de PIMLs. A soma abstrata dados + redes neurais + leis físicas é responsável por produzir modelos especializados de PIMLs, tais como as redes neurais informadas por física (physics-informed neural networks, ou PINNs), solidamente discutidas por Raissi et al. [12] e artigos referenciados. Atualmente, existe uma variedade de PINNs: sPINNs, fPINNs, LePINNs, nPINNs, em que os prefixos “s”, “f”, “Le” e “n” correspondem, nesta ordem, a “stochastic”, “fractional”, “Levy process” e “nonlocal”. Este conceito é um divisor de águas para a engenharia computacional, dadas as vastas possibilidades de integração com métodos numéricos ortodoxos.
Gêmeos digitais
O segmento industrial está sendo fortemente influenciado pela engenharia computacional neste despontar da transformação digital da indústria: a Indústria 4.0. As tecnologias existentes que, até o momento, permearam o setor, notadamente as empregadas em projetos assistidos por computador (CAD, CAE etc.), são agora complementadas por um gêmeo digital (digital twin). Este termo aparentemente nasceu em um programa de pesquisa da NASA no início deste século. Em 2003, deram-lhe a seguinte definição: “um produto digital equivalente ao produto físico”. Mais tarde, um termo equivalente fora “produto avatar”. Mais recentemente, Liu et al. [13] localizaram pelo menos 21 definições diferentes para “gêmeo digital”. Eles registram:
“Anteriormente, a maioria dos artigos definiu gêmeo digital como um modelo de alta fidelidade ou uma simulação multidisciplinar sem considerar a sua conexão em tempo real com o objeto físico. À medida que se aprofundaram, muitos pesquisadores começaram a dar importância à correspondência dinâmica e bidirecional entre o objeto digital e o objeto físico. No entanto, a maioria deles não fez distinção entre um gêmeo digital e um modelo computacional usual.” (com adaptações)
Por outro lado, os mesmos autores sugerem que a idéia básica de um gêmeo digital é simples:
“vincular o objeto físico ao objeto digital de maneira dinâmica“.
À primeira vista, a conexão entre gêmeos digitais e ciência de dados parece frágil, mas o segredo está nos meandros da tecnologia. A construção fiel de um gêmeo digital depende de sensores, medidores, câmeras, escâneres e equipamentos integrados que coletem e transmitam dados em tempo real, grande volume e alta velocidade. Para tudo isso funcionar, há muita carga, processamento e engenharia de dados envolvida, além de protocolos de passagem de mensagem e uso de tecnologia 5G.
A arquitetura tecnológica dos gêmeos digitais compreende:
- processos de datificação: coleta (sensores, câmeras), mapeamento (XML, AutomationML), processamento (edge computing, blockchain) e transmissão de dados (bluetooth, 5G);
- modelagem de alta fidelidade: modelagem física (mecânica, material, hidrodinâmica), semântica (machine learning, deep learning);
- simulações baseadas em modelos: simulação multi-escala, discretização, análise por elementos finitos, interação bidirecional etc.
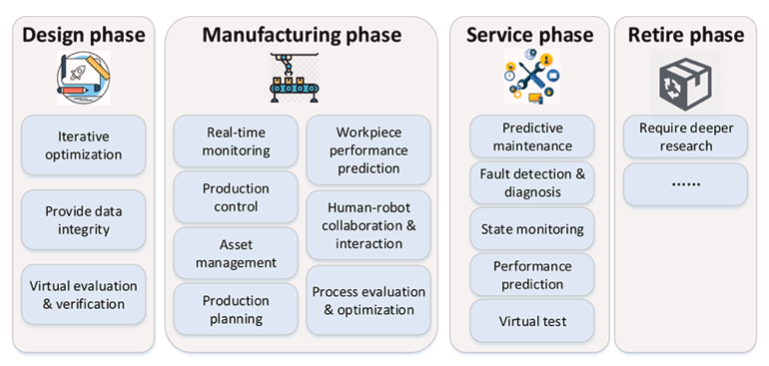
Como se vê, há um vasto campo de atuação tanto para a CSE quanto para a ciência de dados em processos integradores para que o paradigma dos gêmeos digitais funcione perfeitamente. Em termos de aplicações industriais, quatro fases são reconhecidas no ciclo de vida do objeto físico associado: projeto, fabricação, serviços e retirada. Em cada fase, há diversas aplicações dos gêmeos digitais.
Engenharia computacional no enfrentamento da Covid-19
A pandemia da Covid-19 desencadeou enormes desafios para a comunidade global. Concomitantemente, pesquisadores de diversas áreas mobilizaram-se para apresentar estratégias de enfrentamento à doença e propostas para mitigação dos riscos de contaminação do vírus SARS-CoV-2. A CSE não ficou de fora. A dinâmica dos fluidos computacional (computational fluid dynamics, CFD) contribuiu magnificamente para a elaboração de protocolos, equipamentos de proteção individual e coletiva, bem como para controle de engenharia em ambientes hospitalares. A seguir, parafraseamos três objetivos reportados pela Siemens Digital Industries Software em estudos de caso reais guiados por CFD:
- entender a dinâmica espaço-temporal de partículas virais exaladas por seres humanos na forma de gotículas e aerossóis;
- aperfeiçoar o projeto de sistemas de ventilação interior, bem como de exaustão e filtração visando conforto e segurança hospitalar;
- projetar equipamentos respiratórios, dispositivos para esterilização, purificação e produção de vacinas.
A Figura abaixo mostra simulações computacionais da dinâmica de partículas transportadas por um espirro humano em dois cenários de ambiente fechado. O primeiro simula a dinâmica das partículas partindo do nariz de um indivíduo supostamente contaminado aglomerado com outros. O segundo considera a origem do movimento no nariz de um paciente em leito hospitalar na presença de um observador. Ambos os casos mostram como as partículas se dispersam de maneira totalmente aleatória, imprevisível e turbulenta [14].

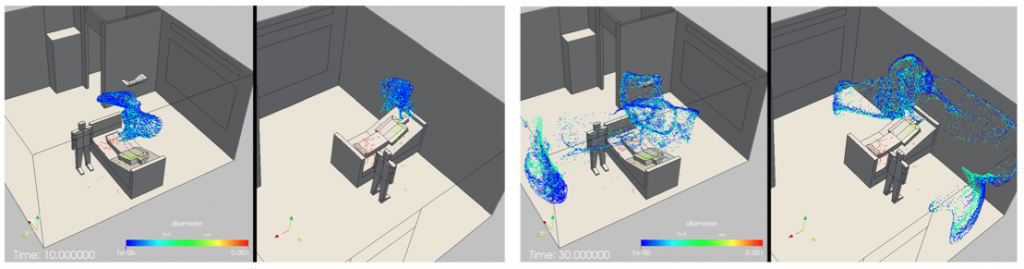
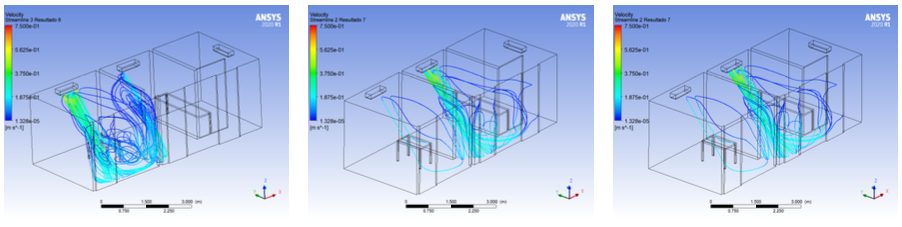
As imagens abaixo, que seguem a mesma linha de interesse, mostram o campo de velocidade do ar produzido por dispositivo condicionador em uma enfermaria do Hospital Universitário Lauro Wanderley (UFPB) para análise de controle de engenharia. As simulações computacionais foram executadas em um modelo computacional com dimensões realistas usando o software Ansys Fluent®. Os resultados desta pesquisa serão reportados brevemente em um artigo científico escrito por membros do TRIL Lab.
Considerações Finais
Apresentamos uma visão geral sobre áreas emergentes interdisciplinares que são de interesse do TRIL Lab e como a ciência de dados, juntamente com a engenharia computacional se relacionam com o objetivo de promover soluções globais. Vimos que a datificação está se consolidando como o quarto paradigma da ciência e que a engenharia será cada vez mais influenciada por uma cultura baseada em dados. No TRIL Lab, defendemos uma formação estratégica e trabalhamos para que nossos alunos e colaboradores se adaptem a um cenário que demanda cada vez mais habilidades flexíveis e interdisciplinaridade. Em um mundo centrado em dados, a engenharia computacional terá um leque incomensurável de oportunidades, compreendendo, modelando e resolvendo problemas de engenharia do mundo real.
Referências
[1] HEY T. et al. The Fourth Paradigm: Data-IntensIve ScientIfIc Discovery, Microsoft Research, ISBN: 978-0-9825442-0-4.
[2] CAO, L. Data Science: A Comprehensive Overview. https://doi.org/10.1145/3076253.
[3] IGUAL, L., SEGUÍ, S. Introduction to Data Science, ISBN: 978-3-319-50016-4.
[4] DONOHO, D. 50 Years of Data Science. https://doi.org/10.1080/10618600.2017.1384734.
[5] AERTS, M. et al. Graduate Education in Statistics and Data Science: The Why, When, Where, Who, and What. https://doi.org/10.1146/annurev-statistics-040620-032820
[6] GIROLAMI, M. Introducing Data-Centric Engineering: An open access journal dedicated to the transformation of engineering design and practice. https://doi.org/10.1017/dce.2020.5
[7] LEY, C., TIBOLT, M. FROMME, D. Data-Centric Engineering in modern science from the perspective of a statistician, an engineer, and a software developer. https://doi.org/10.1017/dce.2020.2
[8] REINSEL, D. et al. The Digitization of the World: From Edge to Core, 2018.
[9] CHIESA, G. Technological Paradigms and Digital Eras: Data-Driven Visions for Building Design, Politecnico de Torino, Springer.
[10] SANTANDER, M. R. et al. On the Pitfalls of Learning with Limited Data: A Facial Expression Recognition Case Study, 2021.
[11] KARNIADAKIS, G. E. et al. Physics-informed machine learning. https://doi.org/10.1038/s42254-021-00314-5.
[12] RAISSI, M. et al. Physics-informed neural networks: a deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. https://doi.org/10.1016/j.jcp.2018.10.045.
[13] LIU, M. et al. Review of digital twin about concepts, technologies, and industrial applications. https://doi.org/10.1016/j.jmsy.2020.06.017.
[14] LÖHNER et al. Detailed simulation of viral propagation in the built environment. https://doi.org/10.1007/s00466-020-01881-7
Autoria: Gustavo Oliveira, professor do DCC/CI/UFPB e co-líder do TRIL Lab.
Imagem de capa: Joshua Sortino, Unsplash.
Atribuição: Licença Creative Commons CC BY SA.